Learning Rate Schedulers (a.k.a) Timestepping
Overview
We demonstrate the behaviour of different learning rate schedulers through solution of a nonlinear inverse problem.
In this example we have a model that produces the exponential of a sinusoid $f(A, v) = \exp(A \sin(t) + v), \forall t \in [0,2\pi]$. Given an initial guess of the parameters as $A^* \sim \mathcal{N}(2,1)$ and $v^* \sim \mathcal{N}(0,25)$, the inverse problem is to estimate the parameters from a noisy observation of only the maximum and mean value of the true model output.
We shall compare the following configurations of implemented schedulers.
- Fixed, "long" step
DefaultScheduler(0.5)- orange - Fixed, "short" step
DefaultScheduler(0.02)- green - Adaptive timestep (designed originally to ensure EKS remains stable)
EKSStableScheduler()Kovachki & Stuart 2018 - red - Adaptive misfit-controlling step (for finite-time algorithms, terminating at
T=1)DataMisfitController(terminate_at=1)Iglesias & Yang 2021 - purple - Adaptive misfit-controlling step (continuation beyond terminate condition)
DataMisfitController(on_terminate="continue")- brown
For typical problems we provide a default scheduler depending on the process. For example, when constructing an Inversion()-type EnsembleKalmanProcess, by default this effectively adds the scheduler
scheduler = DataMisfitController(terminate_at = 1) # adaptive step-sizestop at algorithm time "T=1"To modify the scheduler, use the keyword argument
ekpobj = EKP.EnsembleKalmanProcess(args...; scheduler = scheduler, kwargs...)Several other choices are available:
scheduler = MutableScheduler(2) # modifiable stepsize at each iteration with default "2"
scheduler = EKSStableScheduler(numerator=10.0, nugget = 0.01) # Stable for EKS
scheduler = DataMisfitController(terminate_at = 1000) # stop at algorithm time "T=1000"Please see the learning rate schedulers API for defaults and other details
Early termination (with adaptive learning rate)
When using an adaptive learning rate, early termination may be triggered when a scheduler-specific condition is satisfied prior to the final user prescribed N_iter. See how to set the termination condition for such schedulers in the API documentation. When triggered, early termination is returns a not-nothing value from update_ensembe!( and can be integrated into the calibration loop as follows
using EnsembleKalmanProcesses # for get_ϕ_final, update_ensemble!
# given
# * the number of iterations `N_iter`
# * a prior `prior`
# * a forward map `G`
# * the EKP object `ekpobj`
for i in 1:N_iter
params_i = get_ϕ_final(prior, ekpobj)
g_ens = G(params_i)
terminated = update_ensemble!(ekpobj, g_ens) # check for termination
if !isnothing(terminated) # if termination is flagged, break the loop
break
end
end Note - in this loop the final iteration may be less than N_iter.
Timestep and termination time
Recall, for example for EKI, we perform updates of our ensemble of parameters $j=1,\dots,J$ at step $n = 1,\dots,N_\mathrm{it}$ using
$\theta_{n+1}^{(j)} = \theta_{n}^{(j)} - \dfrac{\Delta t_n}{J}\sum_{k=1}^J \left \langle \mathcal{G}(\theta_n^{(k)}) - \bar{\mathcal{G}}_n \, , \, \Gamma_y^{-1} \left ( \mathcal{G}(\theta_n^{(j)}) - y \right ) \right \rangle \theta_{n}^{(k)},$
where $\bar{\mathcal{G}}_n$ is the mean value of $\mathcal{G}(\theta_n)$ across ensemble members. We denote the current time $t_n = \sum_{i=1}^n\Delta t_i$, and the termination time as $T = t_{N_\mathrm{it}}$.
Adaptive Schedulers typically try to make the biggest update that controls some measure of this update. For example, EKSStableScheduler() controls the frobenius norm of the update, while DataMisfitController() controls the Jeffrey divergence between the two steps. Largely they follow a pattern of scheduling very small initial timesteps, leading to much larger steps at later times.
There are two termination times that the theory indicates are useful
- $T=1$: In the linear Gaussian case, the $\{\theta_{N_\mathrm{it}}\}$ will represent the posterior distribution. In nonlinear case it should still provide an approximation to the posterior distribution. Note that as the posterior does not necessarily optimize the data-misfit we find $\bar{\theta}_{N_\mathrm{it}}$ (the ensemble mean) provides a conservative estimate of the true parameters, while retaining spread. It is noted in Iglesias & Yang 2021 that with small enough (or well chosen) step-sizes this estimate at $T=1$ satisfies a discrepancy principle with respect to the observational noise.
- $T\to \infty$: Though theoretical concerns have been made with respect to continuation beyond $T=1$ for inversion methods such as EKI, in practice we commonly see better optimization of the data-misfit, and thus better representation $\bar{\theta}_{N_\mathrm{it}}$ to the true parameters. As expected this procedure leads to ensemble collapse, and so no meaningful information can be taken from the posterior spread, and the optimizer is not likely to be the posterior mode.
The experiment with EKI & UKI
We assess the schedulers by solving the inverse problem with EKI and UKI (we average results over 100 initial ensembles in the case of EKI). We will not draw comparisons between EKI and UKI here, rather we use them to observe consistent behavior in the schedulers. Shown below are the solution plots of one solve with each timestepper, for both methods.
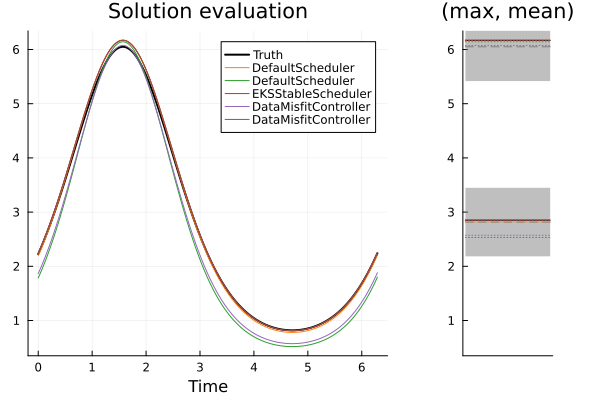
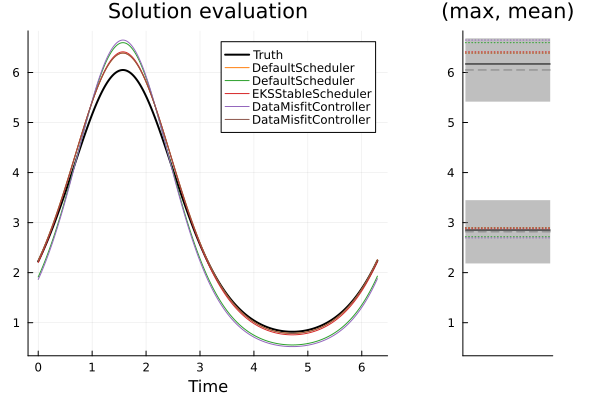
Top: EKI, Bottom: UKI. Left: The true model over $[0,2\pi]$ (black), and solution schedulers (colors). Right: The noisy observation (black) of mean and max of the model; the distribution it was sampled from (gray-ribbon), and the corresponding ensemble-mean approximation given from each scheduler (colors).
To assess the timestepping we show the convergence plot against the algorithm iteration we measure two quantities.
- error (solid) is defined by $\frac{1}{N_{ens}}\sum^{N_{ens}}_{i=1} \| \theta_i - \theta^* \|^2$ where $\theta_i$ are ensemble members and $\theta^*$ is the true value used to create the observed data.
- spread (dashed) is defined by $\frac{1}{N_{ens}}\sum^{N_{ens}}_{i=1} \| \theta_i - \bar{\theta} \|^2$ where $\theta_i$ are ensemble members and $\bar{\theta}$ is the mean over these members.
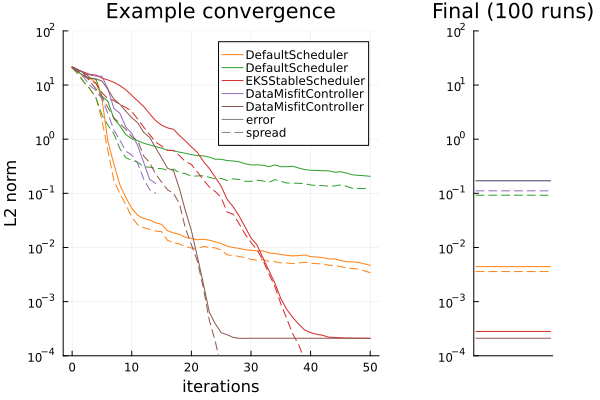
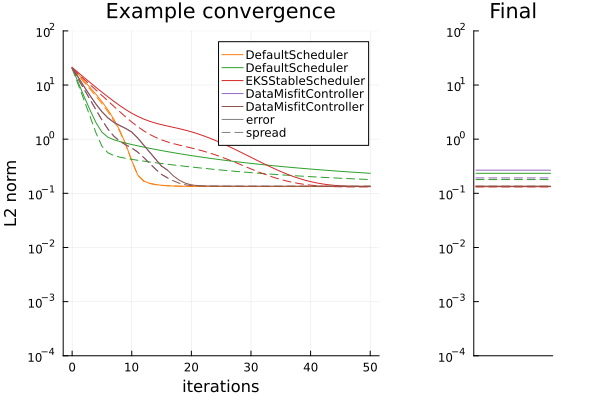
Top: EKI. Bottom: UKI. Left: the error and spread of the different timesteppers at over iterations of the algorithm for a single run. Right: the error and spread of the different timesteppers at their final iterations, (for EKI, averaged from 100 initial conditions).
Finding the Posterior (terminating at $T=1$):
- DMC with termination (purple), closely mimics a small-fixed timestep (green) that finishes stepping at $T=1$. Both retain more spread than other approaches, and DMC is far more efficient, typically terminating after around 10-20 steps, where fixed-stepping takes 50. We see that (for this experiment) this is a conservative estimate, as continuing to solve (e.g. brown) until later times often leads to a better error while still retaining similar "error vs spread" curves (before inevitable collapse). This is consistent with the concept of approximating the posterior, over seeking an optimizer.
- The behavior observed in UKI is similar to EKI
Optimizing the objective function (continuing $T \to \infty$):
- Large fixed step (orange). This is very efficient, but can get stuck when drawn too large, (perhaps unintuitive from a gradient-descent perspective). It typically also collapses the ensemble. On average it gives lower error to the true parameters than DMC.
- Both EKSStable and DMC with continuation schedulers, perform very similarly. Both retain good ensemble spread during convergence, and collapse after finding a local optimum. This optimum on average has the best error to the true parameters in this experiment. They appear to consistently find the same optimum as $T\to\infty$ but DMC finds this in fewer iterations.
- The UKI behavior is largely similar to EKI here, except that ensemble spread is retained in the $T\to\infty$ limit in all cases, from inflation of the parameter covariance ($\Sigma_\omega$) within our implementation.